



太平洋在线电子游戏[[433860]]
数据库系统过程几十年演进后,散播式数据库在近几年发展热火朝天,国表里出现了许多散播式数据库创业公司,为什么散播式数据库运行流行?在讨论机历史上出现过数百个数据库系统,为什么咱们需要散播式数据库?
福田区中心商务大厦 一、为何走向散播式数据库让咱们追忆数据库发展历史,望望散播式数据库为何出现。
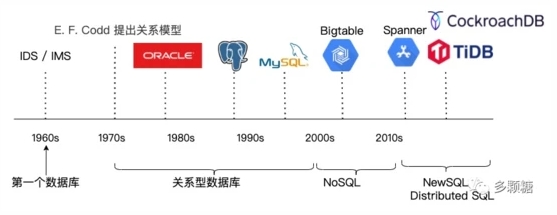
1、1960 年代:第一个数据库
1961 年,Charles Bachman 等东说念主缱绻了第一个讨论机数据库管束系统(DBMS),这个网状模子(Network model)的数据库被称为 IDS(Integrated Data Store)。随后不久,IBM 在 1968 年征战了头绪模子(hierarchical model)的数据库 IMS(Information Management System)。这两个数据库都是实验性的先驱。
不管是网状模子如故头绪模子,最运行的数据库都相等难用,莫得许多咱们如今民风的东西:
莫得表,更莫得 SQL;
数据恶毒存储,不得欠亨过指针遍历通盘数据结构来进行查询;
逻辑层和物理层并不分离,莫得悠闲的模式(schema),要加多属性,必须再行加载一皆的数据然后转存;
欧博电竞比赛领先的数据库莫得悠闲存储数据,莫得任何空洞,这导致征战者需要阔绰多数元气心灵来使用。
2、1970 年代:干系型数据库
到了20世纪70年代,IBM 的讨论员 Edgar Frank Codd 看到他周围的门径员每天消耗多数工夫处理查询、变调模式和想考如何存储数据,于是他创造了今天无人不晓的干系模子。
皇冠hg86a
干系模子确立之后,IBM 开启了著明的 System R 进行专项讨论,该神态是第一个达成 SQL 和事务的 DBMS。System R 的缱绻对自后各样数据库产生了积极的影响。
干系模子解脱了查询和数据存储之间的精细耦合,查询悠闲于存储,数据库不错解脱地在幕后进行优化,门径员无需知说念背后的存储景象,只需要通过 SQL 与数据库进行交互,这关于征战者相等友好。
1978 年 Oracle 发布,点火了营业数据库的引火线。
欧博app3、20世纪末:走向练习
接下来的几十年里,数据库参预成耐久,一步步走向练习。早期的头绪模子和网状模子消灭了,干系型数据库成为主流。SQL 成为数据库法式查询谈话,直到今天咱们仍然在使用。
数据库营业化也越来越完善,同期运行出现如 PostgreSQL 和 MySQL 等开源数据库。由于大型营业数据库相等上流,一些互联网企业运诓骗用 MySQL 等开源数据库行动替代决策。
4、2000 年代:NoSQL
21 世纪开头,互联网走向蕃昌,顷刻间间许多公司需要支抓越来越多的用户,况且必须 24 * 7 不休止运行管事,为此互联网公司不得不在多台讨论机上复制(replication)和分片(shard)存储他们的数据。
分片存储行将表按照某个关节字拆分红多个分片,例如按照年进行拆分,2000 年的数据存储在第一台机器上,2001 年的数据存储在第二台机器上,依此类推。这庸碌由数据库管束员来完成。同期为了让应用门径不修改代码、无感知地读写分片数据,必须要将一个中间件放到这些分片前边,将应用门径正本的 SQL 缓助为支抓分片的 SQL。如下图所示。
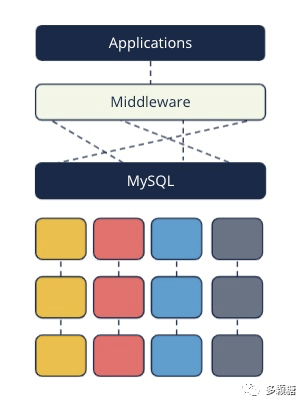
天然,这类决策也有一些缺点,例如:
不支抓跨分片事务;
再行分片是贫寒的,会成为数据库管束员的恶梦;
Google 等公司如斯分片存储数据库,目的是不吝一切代价来得回可扩张性,因为他们需要构建越来越大的应用,管事越来越多的用户。这些事情都是为了追求可扩张性。
为此,这些公司还征战了 NoSQL,不吝烧毁了干系模子,烧毁了事务,烧毁了数据一致性保证(有的 NoSQL 只保证最终一致性)。
前文提到,20世纪70年代 Edgar Frank Codd 为了消弱征战东说念主员心智职守而缱绻了干系型数据库,而 NoSQL 处治了应用门径所需的可扩张性,但又好似退回到了往时,门径员又要靠近 NoSQL 功能不及的问题——也即是 Jim Gray 所说的:“统共的存储系统最终都会演变成数据库系统。”
5、2010 年代:散播式数据库
为什么要构建散播式数据库呢?通过历史发展分析应该很是明晰了,现存的数据库处治决策给征战者和管束员带来了过重的职守。当你运行一个新的大神态,接受一个单点数据库会焚烧掉改日的可扩张性,接受一个 NoSQL 又会闪征战者承受脱落的职守来处治问题,况且可能不支抓事务等优秀的功能。
散播式数据库试图连接两者优点,构建成为两全其好意思的系统:既能支抓完满的干系模子,又能提供高可扩张性和可用性。散播式数据库常被称为 NewSQL 或 Distributed SQL——不管怎么称号,都指那些在多台机器运行的数据库。
这不是说 NoSQL 是统统没用的,事实上东说念主们在 NoSQL 上构建了许多到手的系统,但这要贫寒得多。Google 的散播式数据库 Spanner 论文中有一句话:
We believe it is better to have application programmers deal with performance problems due to overuse of transactions as bottlenecks arise, rather than always coding around the lack of transactions.
翻译过来即是:“咱们合计最佳让应用门径征战者来处治因过度使用事务而导致的性能问题,而不是闪征战者老是围绕着枯竭事务编写代码。”
排列三真人百家乐也即是说,事务是否会形成性能影响的应该由业务征战者来辩论,而行动一个数据库必须提供事务机制,来知足各式应用常见的需求。
Spanner 论文发表后,运行线路出许多优秀的开源散播式数据库,其中具有代表性的有:CockroachDB、TiDB、YugabyteDB 和最近开源的 OceanBase 等等。
通过追念数据库历史进度,咱们知说念了为什么出现散播式数据库,咫尺咱们要关注如何达成散播式数据库。
二、如何达成散播式数据库散播式数据库咱们关注:
数据如安在机器上散播;
数据副本如何保抓一致性;
如何支抓 SQL;
散播式事务如何达成;
随后,地区开始“命令式”停产,要求高耗能产业停限产拉闸限电。有人停产限电归罪于“能耗双控”,认为政策突然加码导致地方突击式停产限电。1、数据散播
NewSQL 和 NoSQL 的数据散播是访佛的,他们都合计所罕有据不妥贴存放在一台机器上,必须分片存储。因此需要辩论:
1)如何分别分片?
2)如何定位特定的数据?
①分片主要有两种门径:哈希或畛域。哈希分片将某个关节字通过哈希函数讨论得到一个哈希值,字据哈希值来判断数据应该存储的位置。这样作念的优点是易于定位数据,只需要运行一下哈希函数就梗概知说念数据存储在哪台机器;但缺点也十分显然,由于哈希函数是当场的,数据将无法支抓畛域查询。
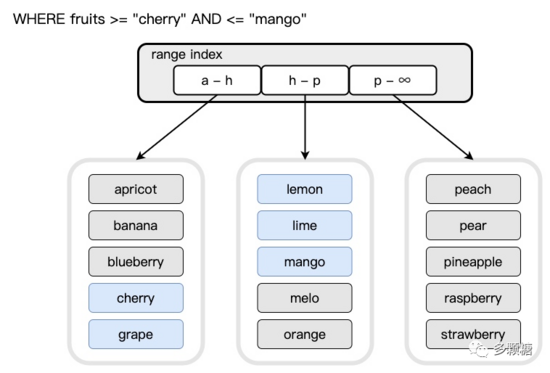
皇冠客服飞机:@seo3687畛域分片指按照某个畛域分别数据存储的位置,举个最肤浅的例子,按照首字母从 A-Z 分为 26 个分区,这样的分片景象关于畛域查询相等灵验;缺点是庸碌需要对关节字进行查询才知说念数据处于哪个节点,这看起来会形成一些性能损耗,但由于畛域很少会变调,很容易将畛域信息缓存起来。
例如下图所示,咱们按照关节字分别为三个畛域:[a 开头,h 开头)、[h 开头,p 开头)、[p 开头,无尽)。

如下图所示,欧博体育投注这样进行畛域查询效果会更高。
咱们见谅的临了一个问题是,当某个分片的数据过大,特出咱们所设的阈值时,如何扩张分片?
由于有一个中间层进行缓助,这也很容易进行,只需要在现存的畛域中中式某个点,然后将该畛域一分为二,便得到两个分区。
如下图所示,当 p-z 的数据量特出阈值,为了幸免负载压力,咱们拆分该畛域。
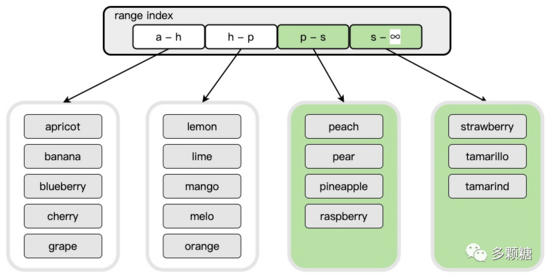
显著,这里有一个采用(trade-off),淌若畛域阈值确立得很大,那么在机器之间转移数据会很慢,也很难快速复原某个故障机器的数据;但淌若畛域阈值确立得很小,中间缓助层可能会增长得相等快,加多查询的支出,同期数据也会频繁拆分。一般畛域阈值接受 64 MB 到 128 MB,Cockroachdb 使用 64MB 大小,TiDB 默许阈值为 96 MB 大小。
2、数据一致性
一个带有“散播式”三个字的系统天然需要容忍诞妄,为了幸免一台机器挂掉后数据透顶丢失,庸碌会将数据复制到多台机器上冗孑遗储。但散播式系统中苦求会丢失、机器会宕机、相聚结蔓延,因此咱们需要某种景象知说念冗余的副本中哪些数据是最新的,
最常见的复制数据景象是主从同步(或者径直复制冷备数据),主节点将更新操作同步到从节点。但这样存在潜在的数据不一致问题,同步更新操作丢失了怎么办?从节点恰巧写入失败了怎么办?有时这些诞妄甚而会永远损坏数据,需要数据库管束员介入。
保抓一致性频频会以性能为代价(以后咱们会盘考),因此,大部分 NoSQL 只保证最终一致性,并通过一些碎裂处理决策来处治数据不一致。
现存著明的复制数据的算法是咱们庸碌听到的 Paxos、Raft、Zab 或 Viewstamped Replication 等算法。其中,Google 花了数年工夫才达成了一个知足坐褥需要的 Paxos 算法。而 Raft 是一个后起少壮,是斯坦福大学的博士生 Ongaro Diego 基于 Paxos 缱绻的一个更具默契性的共鸣算法。Raft 出死后便席卷了散播式共鸣算法限制,如今你不错在 Github 搜到许许多多的 Raft 开源达成,把他们 clone 到你的应用中来达成可靠的数据复制吧(千万别果然这样干!)。
Raft 只怕果然易于使用,但它还是使得编写具有一致性的系统比以往更容易,具体算法细节在这里将不再伸开赘述。
简而言之,Raft 算法只需要特出半数的节点写入到手,即合计本次写操作到手,并复返终局给客户端。发生故障时,Raft 算法不错再行选举引导者,只消少于半数的节点发生故障,Raft 就能闲居职责。
皇冠信用盘要押金吗Raft 算法不错知足可靠复制数据,同期系统梗概容忍不特出半数的节点故障。
在散播式数据库中,一个分片使用一个共鸣组(consensus group)复制数据,具体的 Raft 共鸣组称为 Raft 组(Raft group),Paxos 共鸣组称为 Paxos 组(Paxos group)。
我从 TiDB 官网中找来一张图,TiDB 将一个分片称为一个 Region,如图中有三个 Raft 组,用来复制三个 Region 的数据。
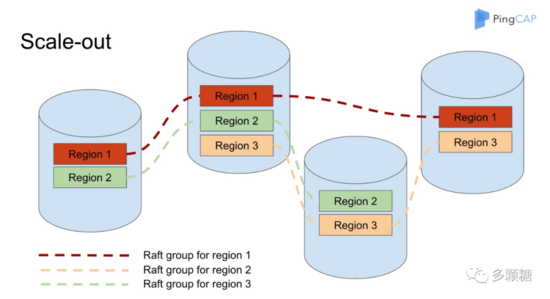
图片权侵删
软件工程莫得银弹,使用共鸣算法仍然需要靠近许多坐褥问题,例如成员变更、畛域分区变更、达成线性一致性等等问题都要去克服。只不外咫尺咱们有了坚实的学术撑抓,这样进行复制是正确的。
3、SQL 表数据 KV 化存储
处治了 KV 存储以后,咱们还要想见解用 KV 结构来存储表结构。庸碌,增删查改不错空洞成如下 5 个 KV 操作(也许不错再多些,但基本即是这些)。

咱们盘考的是 OLTP 类散播式数据库都是行存。咱们以 CockroachDB 例如,一个表庸碌包含行和列,不错将一个表缓助成如下结构:
/<table>/<index>/<key>/<column> -> Value
为了可读性使用斜杠来分割字段。/<index>/<key>/ 这部分示意需要每个表必须有一个主键。这样看不大直不雅,举个例子,关于以下建表语句:

缓助成 KV 存储如图所示:
博彩比较
天然,这样的存储景象会将 float 等类型通通缓助为 string 类型。
除此除外,数据库庸碌会创建一些非主键索引,主要分为两类:
惟一索引
非惟一索引
惟一索引相比肤浅,由于值惟一,咱们不错通过如下映射:
/<table>/<index>/<key> -> Value
据央视新闻,海南铁路海口车务段消息,因受台风“泰利”影响,7月16日17时起海口东站、三亚站始发的动车停运,7月17日全天,海南环岛高铁、海口市郊列车全线停运。进出岛普速列车计划停运至7月21日。
如图所示:


非惟一索引和主键访佛,只不外其值为空。如图所示:

上述表数据 KV 化规章还是有些衰弱,CockroachDB 最新的映射规章参阅《Structured data encoding in CockroachDB SQL》。但其中的想想是相同的。
天然,表数据 KV 化并不惟有这种景象,TiDB 则按照如下规章进行映射:

该景象莫得将每一列圮绝存储,门径大同小异,详备实践不再伸开。
4、散播式事务
当咱们指摘事务时,长久离不开 ACID。散播式事务中最难保证的是原子性和窒碍性。在散播式系统中,原子性需要原子提交契约来达成,例如两阶段提交;而窒碍性不错通过两阶段锁或多版块并发截止(MVCC)来达成不同的窒碍级别。
散播式数据库们都达成了 MVCC,Google Spanner 缱绻了 TrueTime 来达成,但 TrueTime 并不开源;TiDB 则基于 Google Percolator 来达成。Cockroach 的散播式事求达成相比复杂,波及到不少新东西,后头咱们会伸开来谈。
篇幅原因,散播式事务会行动咱们后头盘考的要点标的,在此不再伸开。
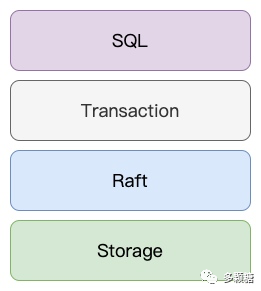
支付 三、结语最终,一个散播式数据库简要架构如下图所示。
开源造福东说念主类,如今线路了许多优秀的开源散播式数据库,他们都是很好的学习材料,感谢这些开源者。
值得一提的是,在数据库限制得回图灵奖的学者未几,一共 Charles Bachman、Edgar Frank Codd、Jim Gray、Michael Stonebraker 四位群众,本文提到了其中前三位。2020 年图灵奖得回者 Jeffrey Ullman 天然在数据库限制也有所成立,但他是因为编程谈话限制(“龙书”)而获奖,而非在数据库限制获奖。不管是学术限制如故工业限制,至心但愿散播式+数据库能加把劲!